基于用户的协同过滤算法(UserCF)
作者:HaloZhang
链接:https://www.jianshu.com/p/f306a37a7374
来源:转载至简书
简介
协同过滤(collaborative filtering)是一种在推荐系统中广泛使用的技术。该技术通过分析用户或者事物之间的相似性,来预测用户可能感兴趣的内容并将此内容推荐给用户。这里的相似性可以是人口特征的相似性,也可以是历史浏览内容的相似性,还可以是个人通过一定机制给与某个事物的回应。比如,A和B是无话不谈的好朋友,并且都喜欢看电影,那么协同过滤会认为A和B的相似度很高,会将A喜欢但是B没有关注的电影推荐给B,反之亦然。
协同过滤推荐分为三种类型:
- 基于用户(user-based)的协同过滤:UserCF算法
- 基于物品(item-based)的协同过滤:ItemCF算法
- 基于模型(model-based)的协同过滤:ModelCF算法
本文主要讲述基于用户的协同过滤算法的原理
算法原理
UserCF算法主要是考虑用户与用户之间的相似度,给用户推荐和他兴趣相似的其他用户喜欢的物品。俗话说"物以群分,人以类聚",人们总是倾向于跟自己志同道合的人交朋友。同理,你朋友喜欢的东西你大概率也可能会喜欢,UserCF算法正是利用了这个原理。举个例子,如果要给一个用户A推荐物品,可以先找到与A最为相似的用户B,接着获取用户B最喜欢的且用户A没有听说过的物品,并预测用户A对这些物品的评分,从中选取评分最高的若干个物品推荐给用户A。
从上述描述可以知道,UserCF算法的主要步骤如下:
找到与目标用户兴趣相似的用户集合
找到这个集合中的用户最喜欢的,且目标用户还未接触过的物品推荐给目标用户
上述是UserCF算法的基本思路,方便读者形成对UserCF算法的整体印象。也许你看了上述文字依然没有思路,没关系,且继续往下看。
首先,根据算法的步骤1,我们自然而然就会提出一个问题,那就是如何度量两个用户之间的相似度?试想一下,我们在现实生活中如何判断两个人是否兴趣相似呢?比如你喜欢打LOL,恰巧你室友也喜欢,那显然你们的共同话题会比较多,因为你们有共同的兴趣爱好。我们刚好可以利用这一点来计算用户之间的相似度。
对于用户u和用户v,令N(u)代表用户u喜欢的物品合集,令N(v)代表用户v喜欢的物品合集。N(u)∩N(v)代表的是用户u和用户v都喜欢的物品,N(u)∪N(v)代表的是用户u和用户v喜欢的物品的合集,那么可以利用以下公式来简单计算相似度:
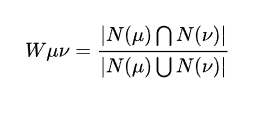
上述公式叫做Jaccard公式,直观上理解就是,将用户u与用户v都喜欢的物品的数量除以他们喜欢物品的总和,如果u和v喜欢的物品是一模一样的,则u和v的相似度为1。
还有另外一种余弦相似度计算公式:
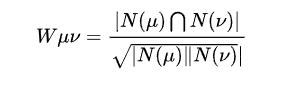
上述公式的分母部分代表的是u喜欢的物品的数量与v喜欢的物品的数量的乘积,而不再是他们之间的交集。
举个简单例子来表明如何计算用户u和v之间的相似度,假如用户u和用户v喜欢的游戏如下表:
| 用户 | 喜爱的游戏 |
|---|---|
| u | {英雄联盟, 王者荣耀,绝地求生} |
| v | {英雄联盟,和平精英} |
利用余弦相似度计算公式可以得到如下结果:

故,我们可以计算得到用户u和用户v之间的相似度为 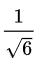
至此,我们已经可以计算任意两个用户之间的相似度了,下一步要做的事情是建立一张用户相似度表,此表中保存了任意两个用户之间的相似度,方便后续挑选出与用户u最相似的若干个用户。
当用户相似度表建立起来了之后,UserCF算法就可以给用户推荐与他兴趣最相似的K个用户喜欢的物品了。那此时又会出现一个问题,假如我们要给用户w进行推荐,并且在用户相似度表中找到了与他最相似的K个用户,这K个用户喜欢的物品有很多,我们怎么知道要推荐哪些物品给用户w呢?此时就涉及到了用户对物品的感兴趣程度,我们当然会把用户最感兴趣的物品推荐给他。故使用以下公式来度量用户u对物品i的感兴趣程度:
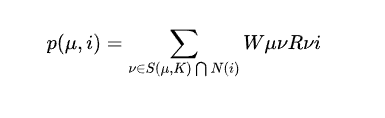

算法工作流程
接下来,我们用一个简单例子演示一下UserCF的具体工作流程。
下表是我们臆造的原始数据,也称之为User-Item表,即用户-物品列表,记录了每个用户喜爱的物品,数据表格如下:
| 用户 | 喜爱的物品 |
|---|---|
| A | {a,b,d} |
| B | {a,c,d} |
| C | {b,e} |
| D | {c,d,e} |
接下来我们需要计算用户相似度矩阵,最直观的方法就是,对于用户列表{A,B,C,D},我们对其中两两用户都使用余弦相似度算法计算相似度。这种算法的时间复杂度是O(N^2),当用户量很大的时候,计算非常耗时,在实际运用中不可取。观察一下相似度计算公式会发现,其实如果用户u和用户v没有共同喜欢的物品(比如表中的用户B和用户C),那么他们之间的相似度为0,也就没有必要计算了。
也就是说我们没必要对任意两个用户之间都计算相似度,我们只需要计算那些彼此之间有共同喜爱物品的用户之间的相似度,故首先可以想到建立倒排表,即Item-User表,具体如下:
| 用户 | 喜爱它的用户 |
|---|---|
| a | {A,B} |
| b | {A,C} |
| c | {B,D} |
| d | {A,B,D} |
| e | {C,D} |
有了这张表之后,相当于我们将原先零散的用户按照他们喜爱的物品给划分成若干个小圈子。比如用户A、B由于都喜欢物品a,所以被分到了一起。同理,用户C、D都喜欢物品e,因此也被分到了一起。
那这么做的目的是什么呢?回顾一下上面说的用户相似度计算方法,可以看到无论是哪一种方法都要先求出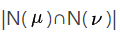 ,所以我们的目的就是为了快速地求出任意用户之间的交集。
,所以我们的目的就是为了快速地求出任意用户之间的交集。
由此可以建立下面的用户喜爱物品交集矩阵W:
| A | B | C | D | |
|---|---|---|---|---|
| A | 0 | 2 | 1 | 1 |
| B | 2 | 0 | 0 | 2 |
| C | 1 | 0 | 0 | 1 |
| D | 1 | 2 | 1 | 0 |
其中Wu代表的含义是用户u和用户v都喜爱的物品个数,即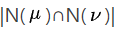 。比如用户A、C都喜欢物品b,所以WA=1。用户A、B除了喜欢物品a以外,还共同喜欢物品d,因此WA=2。
。比如用户A、C都喜欢物品b,所以WA=1。用户A、B除了喜欢物品a以外,还共同喜欢物品d,因此WA=2。
由于用户A、B之间的交集和用户B、A之间的交集是一样的,所以此矩阵是一个对称矩阵。
其实这里的W就是相似度计算公式中的分子部分,而每个用户的喜爱列表从之前的User-Item列表中就已经可以得到了,因此我们就可以计算出用户相似度矩阵了,结果如下:
| A | B | C | D | |
|---|---|---|---|---|
| A | 0 | 0.67 | 0.41 | 0.33 |
| B | 0.67 | 0 | 0 | 0.67 |
| C | 0.41 | 0 | 0 | 0.41 |
| D | 0.33 | 0.67 | 0.41 | 0 |
当用户相似度矩阵建立好了之后,我们就可以对用户进行物品推荐了。
比如要对用户C进行物品推荐,通过查表可以知道(上表第四行),用户A和用户D是比较相似的两个用户。
再通过User-Item表查询到用户A喜欢的物品列表{a,b,d},用户D喜欢的物品列表{c,d,e}, 故用户A、D喜欢物品的交集是{a,b,c,d,e},其中用户C喜欢的列表是{b,e},为了避免重复推荐用户已经喜欢的物品,所以要先从物品列表中去掉用户C已经喜欢的物品,故最终待推荐的物品列表为{a,c,d}。
此时我们来计算用户C对待推荐物品列表中物品的感兴趣程度:
p(C,a) = WC = 0.41
p(C,c) = WC = 0.41
p(C,d) = WC + WC = 0.82
接着按照用户C对待推荐物品感兴趣程度对待推荐列表进行逆序排序,得到最终的推荐列表{d,a,c},我们可以将整个推荐列表或者取前K个物品推荐给用户C。
至此,UserCF算法整体流程结束。
可以看到,算法的输出的最应该推荐给用户C的物品是d,我们不难发现这是因为与用户C最相似的用户A和用户D都喜欢物品d,因此将d推荐给C是比较合理的选择。
相似度算法改进
上述算法使用的是余弦相似度计算公式,但是这个公式过于粗糙,原因是余弦相似度只是简单地计算了用户u和用户v共同喜欢的物品在他们总共喜欢物品中占据的比例。
比如,两个用户都购买了时下热门物品,这并不能说明他们兴趣相似,因为热门物品是绝大多数人都会买的东西。换句话说,两个用户对冷门物品采用过相同的行为更能说明他们兴趣的相似度。因此John.S.Breese提出了以下相似度计算公式:
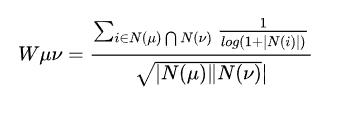
相比余弦相似度公式,这里的分子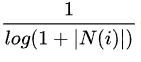 惩罚了用户u和用户v共同喜欢的热门物品对他们相似度的影响。
惩罚了用户u和用户v共同喜欢的热门物品对他们相似度的影响。
代码实践部分参考(所用语言:Python)
作者:HaloZhang
链接:https://www.jianshu.com/p/7c5d9c008be9
来源:简书
版权属于:Monster_4y
本文链接:https://blog.zmonster.top/33.html
转载时须注明出处及本声明

