基于物品的协同过滤算法(ItemCF)
作者:HaloZhang
链接:https://www.jianshu.com/p/f306a37a7374
来源:转载至简书
简介
协同过滤(collaborative filtering)是一种在推荐系统中广泛使用的技术。该技术通过分析用户或者事物之间的相似性,来预测用户可能感兴趣的内容并将此内容推荐给用户。这里的相似性可以是人口特征的相似性,也可以是历史浏览内容的相似性,还可以是个人通过一定机制给与某个事物的回应。比如,A和B是无话不谈的好朋友,并且都喜欢看电影,那么协同过滤会认为A和B的相似度很高,会将A喜欢但是B没有关注的电影推荐给B,反之亦然。
协同过滤推荐分为三种类型:
- 基于用户(user-based)的协同过滤:UserCF算法
- 基于物品(item-based)的协同过滤:ItemCF算法
- 基于模型(model-based)的协同过滤:ModelCF算法
本文主要讲述基于物品的协同过滤算法的原理
算法原理
ItemCF算法是目前业界使用最广泛的算法之一,亚马逊、Netflix、YouTube的推荐算法的基础都是基于ItemCF。
不知道大家平时在网上购物的时候有没有这样的体验,比如你在网上商城下单了一个手机,在订单完成的界面,网页会给你推荐同款手机的手机壳,你此时很可能就会点进去浏览一下,顺便买一个手机壳。其实这就是ItemCF算法在背后默默工作。ItemCF算法给用户推荐那些和他们之前喜欢的物品相似的物品。因为你之前买了手机,ItemCF算法计算出来手机壳与手机之间的相似度较大,所以给你推荐了一个手机壳,这就是它的工作原理。看起来是不是跟UserCF算法很相似是不是?只不过这次不再是计算用户之间的相似度,而是换成了计算物品之间的相似度。
由上述描述可以知道ItemCF算法的主要步骤如下:
计算物品之间的相似度
根据物品的相似度和用户的历史行为给用户生成推荐列表
那么摆在我们面前的第一个问题就是如何计算物品之间的相似度,这里尤其要特别注意一下:
ItemCF算法并不是直接根据物品本身的属性来计算相似度,而是通过分析用户的行为来计算物品之间的相似度。
什么意思呢?比如手机和手机壳,除了形状相似之外没有什么其它的相似点,直接计算相似度似乎也无从下手。但是换个角度来考虑这个问题,如果有很多个用户在买了手机的同时,又买了手机壳,那是不是可以认为手机和手机壳比较相似呢?
由此引出物品相似度的计算公式:



算法工作流程
接下来我们用一个简单例子演示一下ItemCF的具体工作流程。
下表是一个简易的原始数据集,也称之为User-Item表,即用户-物品列表,记录了每个用户喜爱的物品,数据表格如下:
| 用户 | 喜爱的物品 |
|---|---|
| A | {a,b,d} |
| B | {b,c,e} |
| C | {c,d} |
| D | {b,c,d} |
| E | {a,d} |

上图是用户A的共现矩阵C,Ci代表的含义是同时喜欢物品i和物品j的用户数量。举个例子,Ca=1代表的含义就是同时喜欢物品a和物品b的用户有一个,就是用户A。
由于同时喜欢物品i和物品j的人与同时喜欢物品j和物品i的人数是一样的,所以这是一个对称矩阵。
同样的道理,其他用户也都有一张类似的表格。因为不同的用户的喜爱物品列表不一致,会导致每个用户形成的共现矩阵大小不一,这里为了统一起见,将矩阵大小扩充到nxn,其中n是所有用户喜欢物品列表的并集的大小。
下面用一张图来描述如何构建完整的共现矩阵:
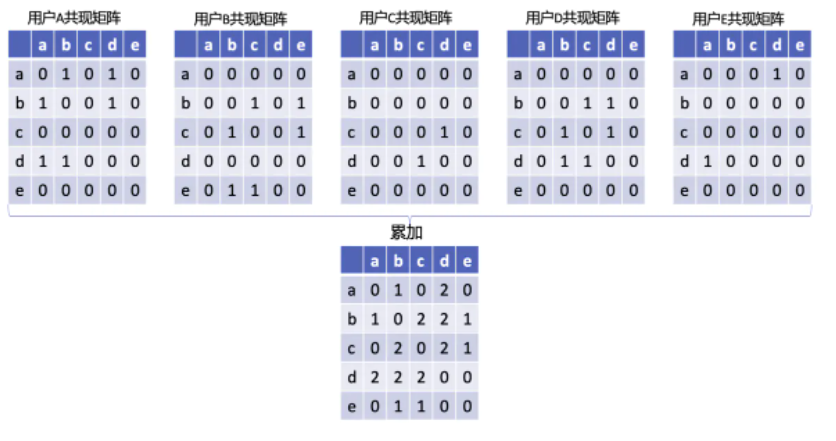
通过对不同用户的喜爱物品集合构成的共现矩阵进行累加,最终得到了上图中的矩阵C,这其实就是相似度公式中的分子部分。

有了物品相似度矩阵W之后,我们对用户进行物品推荐了,下面以给用户C推荐物品为例,展示一下计算过程:
可以看到用户C喜欢的物品列表为{c,d},通过查物品相似度矩阵可知,与物品c相似的有{b,d,e},同理与物品d相似的物品有{a,b,c},故最终给用户C推荐的物品列表为{a,b,e}(注意这里并不是{a,b,c,d,e},因为要去掉用户C喜欢的物品,防止重复推荐)。接下来分别计算用户C对这些物品的感兴趣程度。
相似度算法改进
从前面的讨论可以看到,在协同过滤中两个物品产生相似度是因为它们共同出现在很多用户的兴趣列表中。换句话说,每个用户的兴趣列表都对物品的相似度产生贡献。那么是不是每个用户的贡献都相同呢?
假设有这么一个用户,他是开书店的,并且买了当当网上80%的书准备用来自己卖。那么他的购物车里包含当当网80%的书。假设当当网有100万本书,也就是说他买了80万本。从前面对ItemCF的讨论可以看到,这意味着因为存在这么一个用户,有80万本书两两之间就产生了相似 度,也就是说,内存里即将诞生一个80万乘80万的稠密矩阵。
John S. Breese在论文1中提出了一个称为IUF(Inverse User Frequence),即用户活跃度对数的 倒数的参数,他也认为活跃用户对物品相似度的贡献应该小于不活跃的用户,他提出应该增加IUF 参数来修正物品相似度的计算公式:
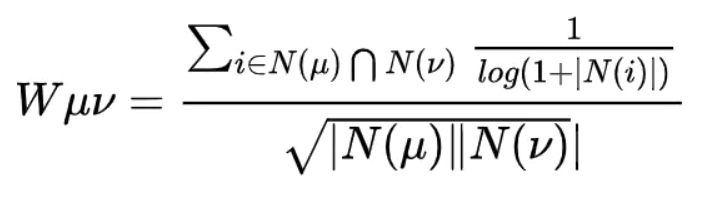
上述公式对活跃用户做了一种软性的惩罚,但是对于很多过于活跃的用户,比如上面那位买了当当网80%图书的用户,为了避免相似度矩阵过于稠密,我们在实际计算中一般直接忽略他的兴趣列表,而不将其纳入到相似度计算的数据集中。
相似度矩阵归一化处理
Karypis在研究中发现如果将ItemCF的相似度矩阵按最大值归一化,可以提高推荐的准确率。其研究表明,如果已经得到了物品相似度矩阵w,那么可以用如下公式得到归一化之后的相似度矩阵w':
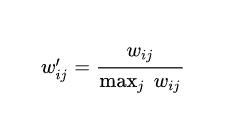
实验表明,归一化的好处不仅仅在于增强推荐的准确度,还可以提高推荐的覆盖率和多样性。
代码实践部分参考(所用语言:Python)
作者:HaloZhang
链接:https://www.jianshu.com/p/f306a37a7374
来源:简书
版权属于:Monster_4y
本文链接:https://blog.zmonster.top/38.html
转载时须注明出处及本声明

